Last week, Mandriva released the 2009 version, because I'm a mandriva fan, immediately I downloaded the One- KDE ISO, burn it and installed in my old HP laptop ( PIII 1 Ghz , 256 Mb RAM, 20 Gb HD , Wi - fi card). The LiveCD run perfectly, show me the new KDE 4 desktop and made a clean install without problems (many others Linux LiveCD have problems just to boot in old hardware like this). I like to use a different partition for the /home, so my partition table looks like: / 5GB swap - 512 MB / geexbox - 100MB /home - rest Yes, I want to install the GeeXBoX , it's great for watch movies. Some good points are the new design, fast boot, the best hardware detection and many friendly menus to configure all. Remarkable is the improved URPMI , it is fast, now support simultaneous package download and the best part is the --auto-orphans option, this check for unused or broken packages and suggest uninstall , cleaning the systems even the kernel, removing unused drivers or m...
I own a little old laptop (it was owned by a very good friend, traded in a perfect time for us). It's a HP pavilion ZT1114, PIII @ 1GHz, only 256 Mb in RAM, no battery, I recently change the HD. The computer is still working well, except for versions of heavy Linux can run but response time is slow. Long time I used in this machine Mandriva , from 2007 to 2009 releases, changing the default desktop to XFCE to save memory and optimizing the system, also I tried Puppy Linux and other minimalistic Linux distributions. But always I feel something missing, an ultimate Linux distro with fast performance. Until few weeks I noted the new release of DreamLinux , a Debian based distro with a pretty and fast desktop (XFCE). I had installed last week and after one week of use, I like it! Everything works well. The AWN bar looks like MacOS X. The Debian stability and large collection of packages. EasyInstall application is really useful. DCP-Control panel works well. Of course not everything w...
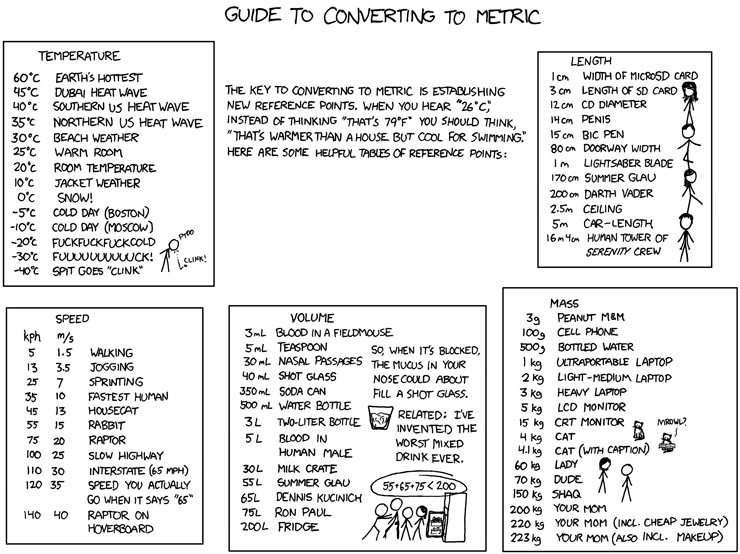


Force them to use the real standards. The should learn and adapt to it.
ReplyDeleteSome data is in metric system (health records for example) but everywhere you found the English system.
ReplyDeleteHow to force them? No way ...
no manches ya lo habia visto , me ahogaba de risa xDDD
ReplyDeletesaludicoch
Marcha: igual me dio mucha gracia, aunque sigo divagando la medida de Summer Glau (ya estoy viendo Terminator: The Sarah Connor Chronicles).
ReplyDelete